A few weeks ago, I decided to build a Raspberry Pi 4 Computing Cluster. Why? I honestly don’t know. I won a bit of money from a Hackathon and instead of saving it up like a good kid, I decided to spend it on little green boards that whirred, purred and fizzled to life when mysterious electron juice flowed through it. After being inspired by a rather expensive hobby that I was shown on the interwebs a few years ago called homelab, I decided to set a mini-version of a homelab in my house with a few Raspberry Pi 4B’s and a network switch.
I presented this to my class the other day and instead of me writing a blog article explaining this stuff, I’m just going to copypasta the presentation while adding a few words here and there because I don’t have too much time to write a detailed explanation.
This is not a tutorial. I don’t have time to write that.
Backstory Time!
Around 2 semesters ago, I had a course called High Performance Computing where we learnt about the Message Passing Interface and hybrid accelerators. A semester after that, I had a course called Distributed Systems where we learnt about the theory behind architectures and the principles that go into designing a distributed system. And now, I’ve elected to take a course called Parallel & Concurrent Programming where we’re learning about the designing parallel algorithms and the thought process that goes into developing conccurent data structures along with implementing these ideas in OpenMP. All these three courses are very similar but focus on different niches of developing code / algorithms designed to run on multiple machines. High Performance Computing on the accelerators, Distributed Systems on the logic & intricacies of making the system itself and Parallel & Concurrent Programming on the actual algorithm design that gets deployed on machines.
The Presentation (in text form) - The Cakejar
Behold! The Cakejar!

Fig 1. The Cakejar
The Cakejar is a Raspberry Pi 4B cluster that is meant to do parallel & distributed computation.
Uses
- Distributed Computing:
- Concurrency
- Network-Latency (Synchronous, Partially Synchronous, Asynchronous)
- Cache Coherence
- Partial Failures
- Fault Tolerances (Fail-Stop / Byzantine Failures
- Redundnacy
- Architectures
- A ton more things
- Distributed Servers:
- FTP / HTTP Servers / Any server, tbh
- Network Attached Storage (RAID / Unraid)
- Distributed Mathematical Computations
- Numerical Methods
- Numerical Solutions of PDEs
- Finite Element Analysis
- Divide & Conquer Algorithms
- Iterative Approachable Algorithms
Components
- 4 x [Raspberry Pi 4B 2Gb RAM]
- Broadcom BCM2711, Quad core Cortex A72 ( ARM v8 ) 64 bit SoC @ 1.5GHz
- 16Gb MicroSD Card
- PoE hats
- Custom 3D Printed Server Rack Compatible Case
- 1 TP Link Network Switch with PoE ports (100 Mbps)

Fig 2. One of the Raspberry Pi 4B's with a PoE hat
To make cable management easier, I went with the slightly more expensive option
of using PoE (Power-over-Ethernet) hats for each Raspberry Pi. This would reduce
one power cable for each Pi as the power was being delivered by the Ethernet
cable. This also meant that the network switch had to have PoE ports, i.e. ports
that supplied power. I found a TP-Link switch that had 8 ports, out of which 4
ports were PoE.

Fig 3. Another angle of the Raspberry Pi 4B

Fig 4. The TP-Link Network Switch with 4 PoE ports
Software
- Each Raspberry Pi 4B runs Raspberry Pi OS Lite
- Debian > Ubuntu > Raspberry Pi OS
- No Display Server, i.e. No Desktop Environment / Window Manager / Graphical User Interface
- Slurm Workload Manager + OpenMPI
Software - Slurm
Slurm is an open source, fault tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. Slurm requires no kernel modifications for its operation and is relatively self contained. As a cluster workload manager, Slurm has three key functions. First, it allocates exclusive and/or non exclusive access to resources (compute nodes) to users for some duration of time so they can perform work. Second, it provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes. Finally, it arbitrates contention for resources by managing a queue of pending work. [https://slurm.schedmd.com/overview.html]
I explained Slurm’s Architecture here, but I’m way too lazy to write all the stuff I explained so instead I’m going to ask you to go to the overview webpage and read about it.
Cakejar - Architecture
Nothing fancy. No hypercube / tesseract / 4-dimensional surface on a 5-dimensional
hyperplane. Just 4 Raspberry Pi’s named after One Piece characters connected to
one network switch
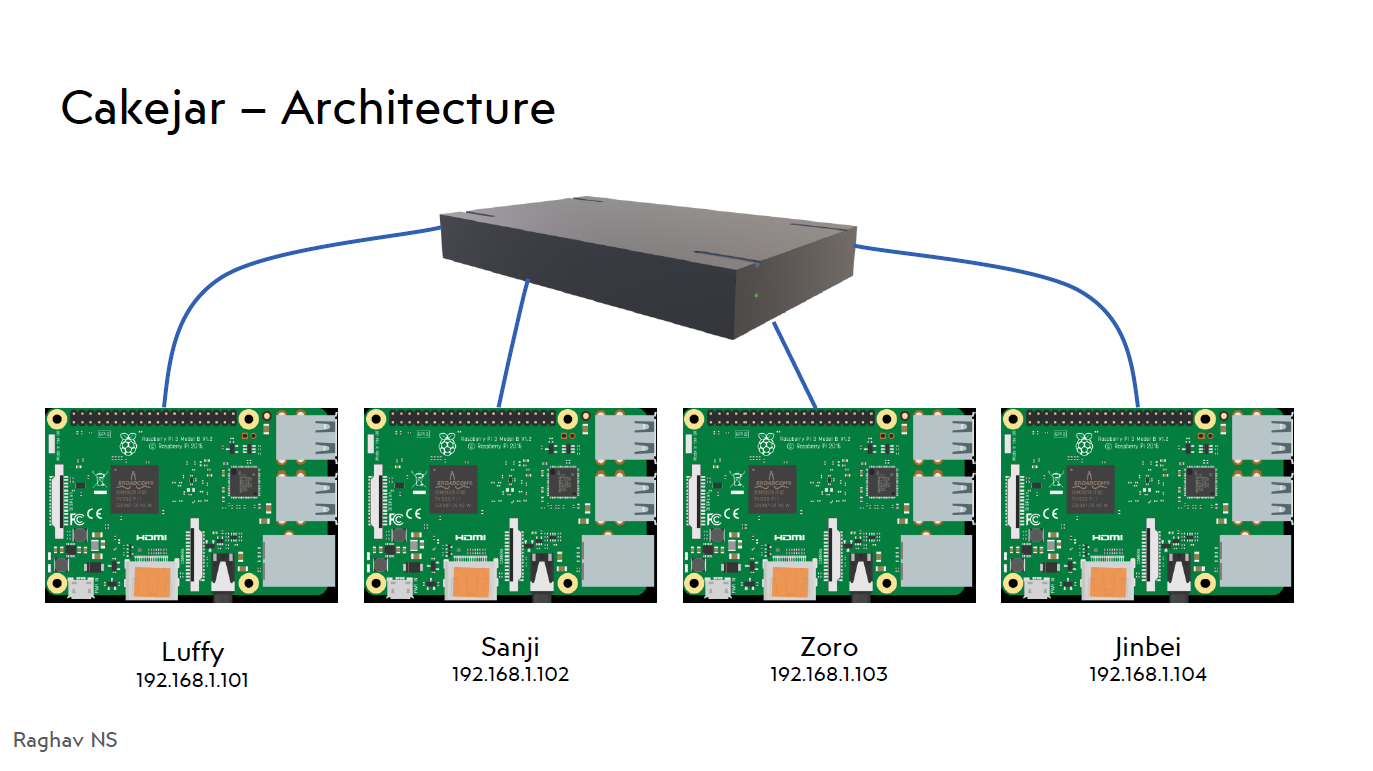
Fig 5. The architecture
Software - OpenMPI
MPI (Message Passing Interface) is a message passing library interface specification. MPI addresses primarily the message passing parallel programming model, in which data is moved from the address space of one process to that of another process through cooperative operations on each process. Extensions to the “classical” message-passing model are provided in collective operations, remote-memory access operations, dynamic process creation, and parallel I/O. MPI is a specification, not an implementation; there are multiple implementations of MPI This specification is for a library interface. MPI is not a language, and all MPI operations are expressed as functions, subroutines, or methods, according to the appropriate language bindings which, for C and Fortran, are part of the MPI standard. The standard has been defined through an open process by a community of parallel computing vendors, computer scientists, and application developers. [https://www.mpi-forum.org/docs/]. OpenMPI is one of the implementations.
Not to be confused with OpenMP - a specification for a set of compiler directives, library routines, and environment variables that can be used to specify high level parallelism in Fortran and C/C++ programs.
The Goal
- The goal is to experiment with Distributed Systems and Parallel Computing
- Personal Interests include:
- Networks
- Distributed Servers, Protocols, File Systems (IPFS)
The Setup
- First try was with
mpichandOpenMP. - What ensued was a week of frustration as every MPI program compiled, but always SegFaulted.
- After looking via GDB, then Valgrind and even strace, I found something wrong with the linking of
/lib/arm-linux-gnueabihf/libthread_db.so.1. - I tried turning it off and on again. Didn’t work.
- I tried to fix it for three days. Didn’t work.
- I reinstalled the OS. Twice. Didn’t work.
I decided to throw everything in the trash and cry.- I decided to go with a different set of software - Slurm with OpenMPI
- It worked.
I cried tears of joy- Installed NFS (The network-file-system, not Need For Speed)
- Appended to
/etc/hostsand/etc/exports - Installed
munge
Benchmarks
Note: 1 task is when the program ran on 1 CPU core on one of the Pi’s. 16 tasks is when the program ran on 16 CPU cores spread over 4 Pi’s.
Mandlebrot Source Code: mandelbrot.py
Mandelbrot [4 nodes 4 threads each -> 16 tasks]:
- 128 iterations –
- 1 task: 244.85 seconds
- 16 tasks: Mean: 18.06 seconds | Max: 19.37 seconds | Sum: 288.92 seconds
- Speedup: 12.64
- 256 iterations –
- 1 task: 381.62 seconds
- 16 tasks: Mean: 26.05 seconds | Max: 26.34 seconds | Sum: 416.80 seconds
- Speedup: 14.48
- 512 iterations –
- 1 task: 682.12 seconds
- 16 tasks: Mean: 45.26 seconds | Max: 45.56 seconds | Sum: 724.12 seconds
- Speedup: 14.97
- 1024 iterations –
- 16 tasks: Mean: 84.00 seconds | Max: 84.31 seconds | Sum: 1343.99 seconds
- 2048 iterations –
- 16 tasks: Mean: 158.33 seconds | Max: 158.65 seconds | Sum: 2533.36 seconds
- 16 tasks: Mean: 158.33 seconds | Max: 158.65 seconds | Sum: 2533.36 seconds

Fig 6. The resultant of the Mandlebrot Program
Unfortunately for this presentation, I didn’t have any other program tested and hence could provide only this benchmark. I have more lined up, but this is all I have for now.
Temperatures
The temperatures seem to be quite good because of the tiny PoE hat’s fan. None
of the Pi’s cross 55°C and the most I’ve seen any Pi go up to is 68°C, which was
when the hot air was being recirculated.
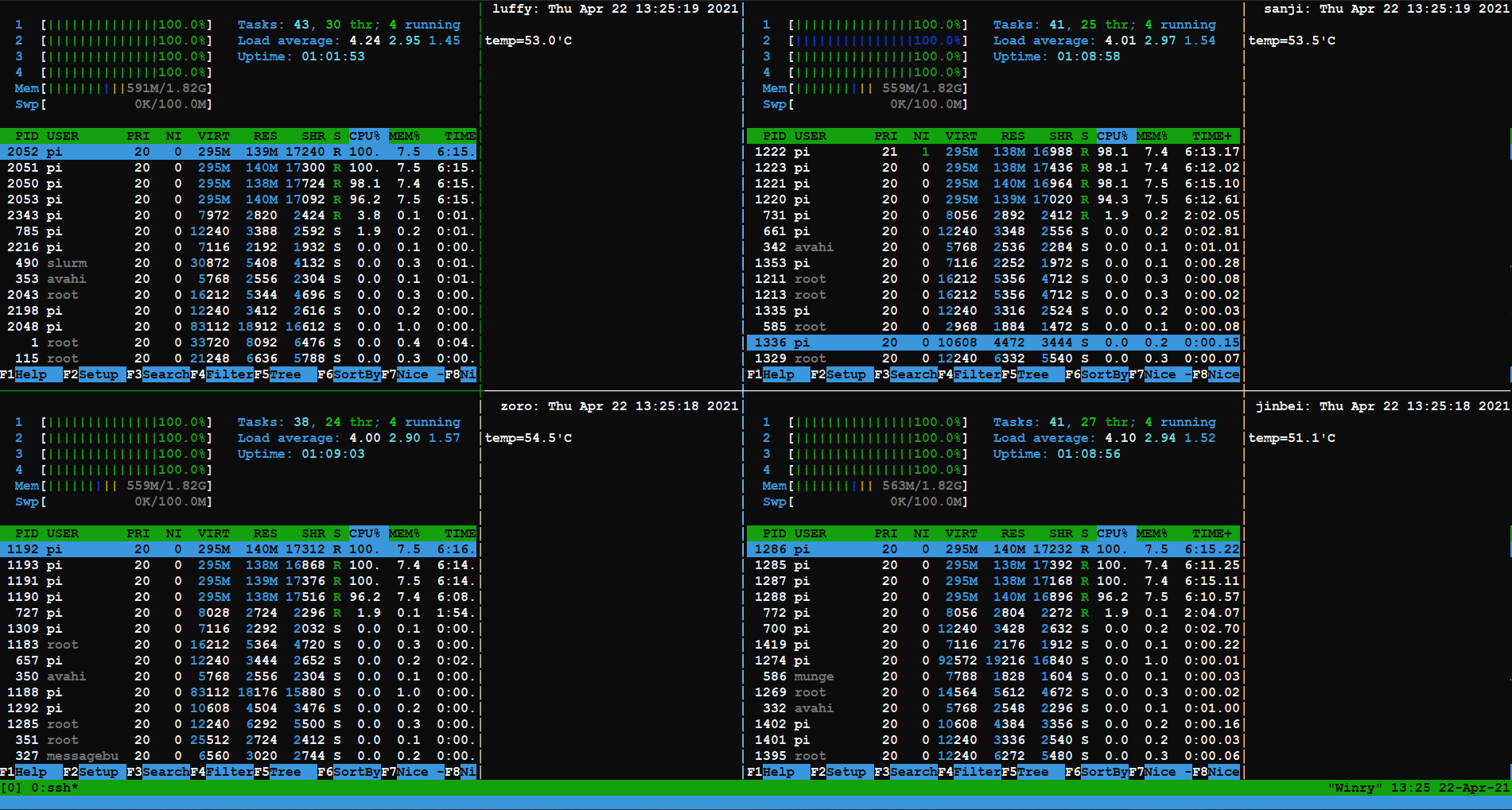
Fig 7. The temperatures of the Pi's
To-Do
I still have to execute a few more programs to benchmark - especially the set of benchmark programs devised by Ohio State University https://mvapich.cse.ohio-state.edu/benchmarks/.
I want to write a few programs that employ numerical methods and then later work on some networking programs (for distributed servers…? still have to figure it out).
./cakejar.sh
This is a teeny-tiny utility script to launch 1 tmux session with 4 panes and ssh into all four Pi’s at once.
tmux new-session \; \
send-keys 'ssh pi@luffy' C-m \; \
split-window -h \; \
send-keys 'ssh pi@sanji' C-m \; \
split-window -v \; \
send-keys 'ssh pi@jinbei' C-m \; \
select-pane -t 0 \; \
split-window -v \; \
send-keys 'ssh pi@zoro' C-m \; \
select-pane -t 0 \;
The End
Post-Script
Crimping ethernet cables is a pain.
No, the Pi’s aren’t in a shoe-box. They’re in a cardboard box that I found and put them in there for easy moving.
This is not a tutorial. I don’t have time to write that.
References
Raspberry Pi OS’s
Slurm Workload Manager
https://ipfs.io/ | ipfs-p2p-file-system.pdf
https://www.mpi-forum.org/docs/
Advanced MPI Programming (Argonne National Laboratory)
Hybrid Accelerator Working Group – Issues (Slides for Proposals)
Hybrid MPI and OpenMP Parallel Programming
Python3.8
mpi4py
http://nfs.sourceforge.net/
mandelbrot.py
http://mvapich.cse.ohio-state.edu/benchmarks/
https://github.com/tmux/tmux/wiki